LightGBM Python quick start
Data Interface
The LightGBM Python module can load data from:
1.libsvm/ tsv / csv / txt format file
2.NumPy 2D array(s), pandas DataFrame, H2O DataTable’s Frame, SciPy sparse matrix
3.LightGBM binary file
The data is stored in a Dataset object.
To load a libsvm text file or a LightGBM binary file into Dataset:
To load a numpy array into Dataset:
Saving Dataset into a LightGBM binary file will make loading faster:
Create validation data:
or
In LightGBM, the validation data should be aligned with training data.
Specific feature names and categorical features:
LightGBM can use categorical features as input directly. It doesn’t need to convert to one-hot coding, and is much faster than one-hot coding (about 8x speed-up).
Note: You should convert your categorical features to int type before you construct Dataset.
Weights can be set when needed:
or
And you can use Dataset.set_init_score() to set initial score, and Dataset.set_group() to set group/query data for ranking tasks.
Memory efficient usage:
The Dataset object in LightGBM is very memory-efficient, it only needs to save discrete bins. However, Numpy / Array / Pandas object is memory expensive. If you are concerned about your memory consumption, you can save memory by:
- Set free_raw_data=True (default is True) when constructing the Dataset
- Explicitly set raw_data=None after the Dataset has been constructed
- Call gc
Setting Parameters
LightGBM can use either a list of pairs or a dictionary to set Parameters. For instance:
Booster parameters: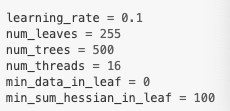

You can also specify multiple eval metrics:
Training
Training a model requires a parameter list and data set:
After training, the model can be saved:
The trained model can also be dumped to JSON format:
A saved model can be loaded:
CV
Training with 5-fold CV:
Early Stopping
If you have a validation set, you can use early stopping to find the optimal number of boosting rounds. Early stopping requires at least one set in valid_sets. If there is more than one, it will use all of them except the training data:
The model will train until the validation score stops improving. Validation score needs to improve at least every early_stopping_rounds to continue training.
The index of iteration that has the best performance will be saved in the best_iteration field if early stopping logic is enabled by setting early_stopping_rounds. Note that train() will return a model from the best iteration.
This works with both metrics to minimize (L2, log loss, etc.) and to maximize (NDCG, AUC, etc.). Note that if you specify more than one evaluation metric, all of them will be used for early stopping. However, you can change this behavior and make LightGBM check only the first metric for early stopping by creating early_stopping callback with first_metric_only=True.
Prediction
A model that has been trained or loaded can perform predictions on datasets: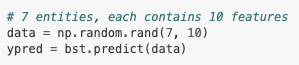
If early stopping is enabled during training, you can get predictions from the best iteration with bst.best_iteration: